
If you’ve ever manually searched job boards every day, you’ll know how time-consuming and repetitive it can be. In this blog, I’ll walk you through how I automated this process by building a job scraper that collects job listings from platforms like LinkedIn or Indeed and saves the data for further analysis.
Whether you’re a developer looking for your next gig or a data enthusiast wanting to build a real-world project, this guide is for you.
🔧 Tools & Libraries I Used
To make this project efficient and scalable, I used:
Python – The core scripting language
requests– To fetch HTML pageslxml– For fast and flexible HTML parsingpandas– To clean and save scraped datafake_useragent– To rotate user agentsOptional:
Selenium– If dealing with dynamic JavaScript content
🎯 Project Goal
Automatically track new job postings for a specific role, location, or keyword, and export them into a CSV file for analysis or personal use.
🌐 Step 1: Identify the Structure of Job Listings
Go to LinkedIn or Indeed, perform a job search, and inspect the HTML structure using your browser’s developer tools. Each listing typically contains:
Job title
Company name
Location
Posting date
Job link or description preview
👉 I used XPath with lxml to target these elements precisely.

📦 Installing Required Libraries
Before running the script, make sure you have the necessary Python libraries installed. You can do this using pip:
pip install requests lxml pandas
If you’re using a virtual environment, activate it first, then run the above command.
These libraries allow your script to fetch web pages (requests), parse the HTML content (lxml), and organize the scraped data into structured tables (pandas).
🧪 Step 2: Make the Request and Parse the Content
Here’s a simplified version of how I scraped job titles and companies from a sample Indeed page:
def crawl_job(self, company_name, location):
flag = True
start = 0
batch_size = 10
id_list = []
while flag:
try:
url = (
f"https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/"
f"search?keywords={company_name}&location={location}&start={start}"
)
response = requests.get(url)
print(response.status_code)
dom = html.fromstring(response.text)
page_jobs = dom.xpath(
"//div[contains(@class, 'base-card')]/@data-entity-urn | "
"//a[contains(@class, 'base-card')]/@data-entity-urn"
)
for job in page_jobs:
job_id = job.split(":")[-1]
id_list.append(job_id)
start += batch_size
except Exception as e:
flag = False
return id_list
⚠️ Note: LinkedIn may throttle your requests if you send too many too fast. Consider adding delays and rotating headers for large-scale scraping.
📥 Extracting Detailed Job Information from LinkedIn
Once we’ve collected all the job IDs, the next step is to scrape detailed job information for each one. This is where the grab_data method comes in.
🔍 What This Function Does
The grab_data method takes a list of job IDs and sends a request to LinkedIn’s internal job posting endpoint. It parses each page and extracts the relevant fields using XPath.
Here’s a step-by-step breakdown:
def grab_data(self, id_list):
count = len(id_list)
job_list = []
for job_id in id_list:
try:
job_url = f"https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/{job_id}"
job_response = requests.get(job_url)
dom = html.fromstring(job_response.text)
Each job posting page is parsed into a DOM tree. Then we define a helper function to simplify text extraction using XPath:
def extract_text(xpath_expr):
result = dom.xpath(xpath_expr)
return result[0].strip() if result else 'Not Available'
We use this to build a dictionary of job data:
job_post = {
"Job Title": extract_text("//h2[contains(@class, 'topcard__title')]/text()"),
"Company Name": extract_text("//a[contains(@class, 'topcard__org-name-link')]/text()"),
"Location": extract_text("//span[contains(@class, 'topcard__flavor--bullet')]/text()"),
"Time Posted": extract_text("//span[contains(@class, 'posted-time-ago__text')]/text()"),
"num_applicants": extract_text("//figcaption[contains(@class, 'num-applicants__caption')]/text()"),
"Seniority level": extract_text("(//span[contains(@class, 'description__job-criteria-text')])[1]/text()"),
"Employment type": extract_text("(//span[contains(@class, 'description__job-criteria-text')])[2]/text()"),
"Job function": extract_text("(//span[contains(@class, 'description__job-criteria-text')])[3]/text()"),
"Industries": extract_text("(//span[contains(@class, 'description__job-criteria-text')])[4]/text()"),
"URL": extract_text("//a[contains(@class, 'topcard__link')]/@href"),
}
job_list.append(job_post)
The function returns a list of job dictionaries, ready for export to CSV, a database, or any dashboard.
✅ Pro Tip: You can add a delay with time.sleep() to avoid hitting LinkedIn’s rate limits too quickly.
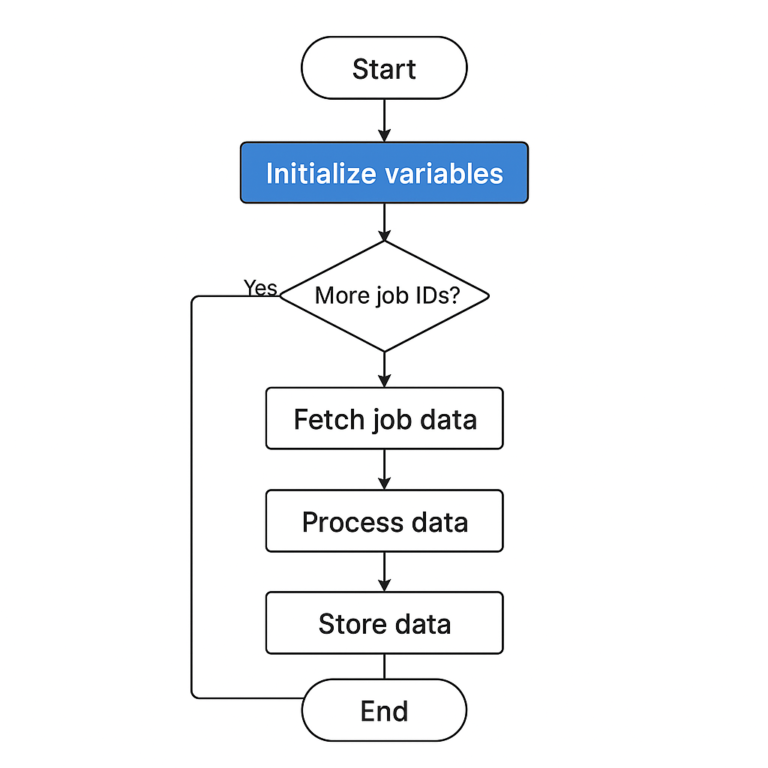
💾 Saving the Data to a CSV File
Once the job IDs are scraped and detailed data is extracted, we convert the results into a structured Pandas DataFrame and save it as a .csv file:
if __name__ == "__main__":
linkedin = LINKEDIN()
id_list = linkedin.crawl_job("zepto", "India")
data = linkedin.grab_data(id_list)
jobs_df = pd.DataFrame(data)
jobs_df.to_csv('zepto.csv', index = False)
✅ This will generate a file named zepto.csv in your working directory, containing all job listings related to Zepto in India.
📁 You can open the CSV in Excel, Google Sheets, or load it into a data analysis tool like Power BI or Tableau.
📂 Get the Full Code on GitHub
You can find the complete source code for this LinkedIn job scraper project on my GitHub:
🔁 Bonus: Automate the Scraper
Use a scheduler like cron (Linux/macOS) or Task Scheduler (Windows) to run the scraper every day and keep your job CSV up to date. You could also add email notifications using smtplib or save listings to a database.
🧼 Common Challenges
Dynamic Content: LinkedIn often loads listings with JavaScript. Use Selenium or Playwright to render and scrape content.
Bot Detection: Rotate user agents and use delay with
time.sleep()to avoid being blocked.Pagination: Loop through multiple result pages by incrementing page numbers in the URL.
📊 What You Can Do with the Data
Visualize trends (e.g., most hiring companies, location heatmaps)
Filter jobs by keywords or remote options
Get alerts when new jobs are posted
Build a personal job dashboard
🚀 Final Thoughts
Building a job scraper not only saves time but also teaches you real-world scraping techniques you can apply across industries. Whether you’re tracking opportunities for yourself or helping others do the same, this project is a perfect mix of automation, data, and practical impact.
If you’re interested in the full code or want help extending the project, drop a comment or connect with me on LinkedIn.