
Have you ever wanted to extract real estate data like price, address, or the number of bedrooms directly from Zillow? In this post, I’ll walk you through how I built a scraper that does exactly that—starting from collecting all Zillow listing IDs in a specific area to extracting detailed property data from each listing.
🚨 Disclaimer: Scraping websites like Zillow should be done responsibly and for educational purposes only. Always read and respect the site’s robots.txt and terms of service.
Why Scrape Zillow Data?
Zillow is one of the largest real estate platforms, offering:
Property listings (for sale, rent, recently sold)
Pricing trends (historical prices, Zestimate)
Neighborhood insights (schools, crime rates, walkability)
Automating data extraction helps with:
✅ Market research – Track price changes in a neighborhood.
✅ Investment analysis – Identify undervalued properties.
✅ Competitor monitoring – Compare real estate agency listings.
But scraping Zillow isn’t straightforward—it requires smart handling of anti-bot measures and efficient data extraction.

How My Zillow Scraper Works
My scraper follows a two-step approach:
Collecting All Zillow IDs in a Target Area
Instead of scraping each listing one by one, I first extract all Zillow IDs (zpid) from search results.
Key Steps:
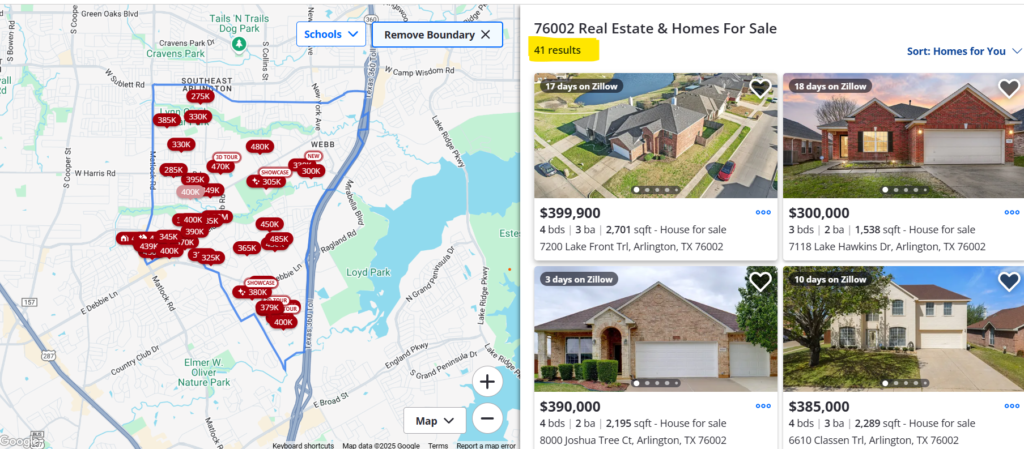
Search for a location (e.g., “76002”) and fetch the listings page.
Parse the HTML to extract
zpidvalues (found in URLs or hidden metadata).Handle pagination to scrape all available listings (not just the first page).
Example Code Snippet (Python with BeautifulSoup):
import requests
import json
from lxml import html
import math
import logging
Getting the Total House Listings
class ZILLOW:
def total_property(self, zipcode):
try:
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language': 'en-US,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': 'https://www.zillow.com/',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'sec-gpc': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
}
response = requests.get(f'https://www.zillow.com/{zipcode}/sold/1_p/', headers=headers)
dom = html.fromstring(response.content)
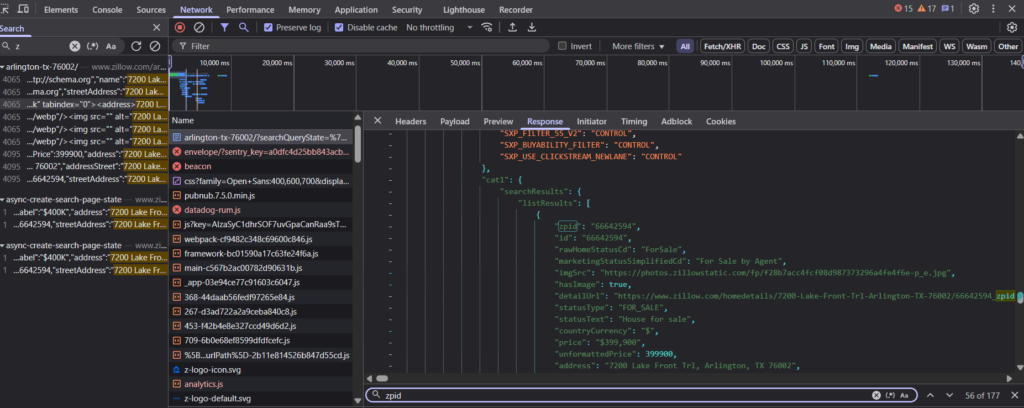
json_data = dom.xpath("//script[contains(@id, '__NEXT_DATA__')]/text()")[0]
data = json.loads(json_data)
total_count = data['props']['pageProps']['searchPageState']['cat1']['searchList']['totalResultCount']
print(total_count)
return total_count
except Exception as e:
logging.error(f"{e}")
return None
Extracting zpid for every house listings
def scraper(self, zipcode, total_count):
pages = math.ceil(total_count/41)
final_list = []
for page in range(1, pages+1):
try:
dict1 = {}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language': 'en-US,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': 'https://www.zillow.com/mansfield-tx-76063/sold/20_p/?',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'sec-gpc': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
}
response = requests.get(f'https://www.zillow.com/{zipcode}/sold/{page}_p/', headers=headers)
dom = html.fromstring(response.content)
json_data = dom.xpath("//script[contains(@id, '__NEXT_DATA__')]/text()")[0]
data = json.loads(json_data)
zpids= data['props']['pageProps']['searchPageState']['cat1']['searchResults']['listResults']['zpid']
final_list.extend(zpids)
if page == 25:
return final_list
except Exception as e:
logging.error(e)
continue
return final_list
🧼 Common Challenges
CAPTCHAs: Zillow may block too many requests. Try services like ScraperAPI, Zyte, or rotating proxies like Bright Data.
Dynamic Content: Some content is JavaScript-rendered. You can use Selenium or Playwright to render pages headlessly.
IP Blocks: Rotate user agents and IPs using libraries like
fake_useragent.
📊 What Can You Do With This Data?
Analyze real estate trends in your city
Compare neighborhoods
Find underpriced properties
Train a house price prediction model using scikit-learn
Build a mini Zillow clone
✨ Final Thoughts
Web scraping gives you the superpower to gather structured data from websites like Zillow—but with great power comes great responsibility. Always follow ethical scraping practices and stay within legal bounds.
Want to dive deeper or need help setting up your own scraper? Drop a comment or connect with me on LinkedIn.
📥 Get the Code
I’ll be uploading the full script to GitHub soon. Until then, subscribe to my blog ScrapeWithMe.com for updates, tutorials, and exclusive tips!